| Research Article |
Open Access |
|
| UM Okeh |
| Department of Industrial Mathematics and Applied Statistics, Ebonyi State University Abakaliki, Nigeria |
| *Corresponding authors: |
UM Okeh
Department of Industrial Mathematics and Applied Statistics
Ebonyi State University Abakaliki, Nigeria
E-mail: umokeh1@yahoo.com |
|
| |
| Received December 01, 2012; Published July 25, 2012 |
| |
| Citation: Okeh UM (2012) Model Determination of the Social-Demographic Risk Factors Affecting the Occurrence of Second Primary Cancer. 1: 178. doi:10.4172/scientificreports.178 |
| |
| Copyright: © 2012 Okeh UM. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited. |
| |
| Abstract |
| |
| The logistic regression model is used to determine the social-demographic risk factors which affect the second cancer occurrence for 200 patients who were initially treated for first primary cancer stage I and were cancer free for at least 1 year after first primary cancer treatment. The 200 patients were classified as "having a second cancer", and "not having a second cancer". The social-demographic risk factors used are age at first cancer, gender, area the patient lives in, marital status, family history, smoking, education and obesity in addition to treatment by radiation. The binary Logistic regression model is used in this study to estimate the probability of the occurrence and to determine the effective risk factors that cause the second cancer occurrence. The odds ratio analysis compare whether the probability of having a second primary cancer is the same for each covariate groups. Significance testing for the logistic coefficients using Wald test and likelihood ratio show that five risk factors were significant. To assess the fitness of the model the Hosmer and Lemeshow test is used. The logistic regression model proved to have a lower sensitivity level due to the clinical risk factors not considered in this study. |
| |
| Keywords |
| |
| Logistic regression model; Wald test; Odds ratio; Crossvalidation; Roc curve; Second primary cancer |
| |
| Introduction |
| |
| Early detection and evaluation of the risk factors which might cause the occurrence of second cancer is very important. The prediction of risk factors is an important pivot of the war against cancer. The use of statistical methods to identify risk factors would help to identify the probability of second cancer occurrence. We distinguish between two medical cases: |
| |
| a). Recurrence case-Cancer that has recurred (come back), usually after a period of time during which the cancer could not be detected. The cancer may come back to the same place as the original (primary) tumor or to another place in the body. Also called recurrent cancer and (b) Second cancer-A new primary cancer in a person with a history of another cancer. According to DeVita et al [1], second cancers can reflect the late sequel of treatment, as well as the influence of lifestyle factors, environment exposures, host determinants and gene-gene interactions. The main life style factors are tobacco and alcohol; the environmental factors are: contaminants and viruses; and the host factors are gender, age, genetics, immune function and hormonal factors. A statistical model is proposed to explain the association between the studied covariates and its effect on the probability of the second cancer occurrence. Data included 200 patients were have a first primary cancer stage I, and have at least one year free cancer after first cancer treatment. Covariates used in the analysis were Age at first Cancer, Gender, Marital status, Area the patient lives in, Treatment by Radiation, Family History, Smoking, Obesity, and Education status. This study proposes to: |
| |
| Determine the effective risk factors that cause the second cancer occurrence and propose a statistical model to explain the association between the studied covariates and second cancer occurrence. Explain the relative risk for each studied covariate and its effect on the probability of the second cancer occurrence. |
| |
| In Section 4, we present the logistic regression model to estimate the probability of occurrence of second cancer; the Wald test, likelihood ratio test, Hosmer-Lemeshow test, cross validation methods and ROC curve are also introduced in section 4. In Section 5, we apply the binary regression model to the data; SPSS is used for the analysis. Summary and conclusions are given in Section 6. |
| |
| The Binary Logistic Regression Model |
| |
| The logistic regression model has been used in many disciplines including medical studies. It has been used in the social research [2- 5], in market research [6-10], also become an important tool at the commercial applications [11 -13]; and in medical studies [14-16]. |
| |
| The dependent variable of the logistic model is classified into two basic types [17]; |
| |
| a. Continuous Variable: can assume any value within a specified range. |
| |
| b. Discrete Variable: can only assume certain values and there are usually “gaps” between values (categorical response has two main categories: success (occurrence) and fail (no occurrence)). Everitt [18] gave the following definition for logistic distribution:" the limiting probability distribution as n tends to infinity, of the average of the largest to smallest sample values, of random samples of size n from an exponential distribution". |
| |
| The logistic distribution is given by |
| |
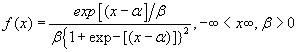 |
| |
The location parameter α is the mean. The variance of the distribution is 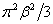 , its skewness is zero and its kurtosis is 4.2. The standard logistic distribution withα = 0,β =1 , with cumulative probability function. F(x), and probability distribution, f(x), has the property f (X ) = F(X )[1− F(x)] see also, [19]. , its skewness is zero and its kurtosis is 4.2. The standard logistic distribution withα = 0,β =1 , with cumulative probability function. F(x), and probability distribution, f(x), has the property f (X ) = F(X )[1− F(x)] see also, [19]. |
| |
| The logistic regression is a form of regression analysis used when the response variable is a binary variable [18,20]. The method is based on the logistic transformation or logit proportion, namely; |
| |
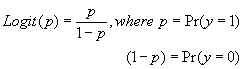 |
| |
As p tends to 0, Logit (p) tends to ∞ – and as p tends to 1, Logit (p) tends to −∞ . The function Logit (p) is a sigmoid curve that is symmetric about p = 0.5.The logistic regression makes no assumption about the distribution of the independent variables. They do not have to be normally distributed, linearly related or of equal variance within each group. The relationship between the predictor and response variables is not a linear function in logistic regression. The logistic regression function is the logit transformation of P, where;  Where β 0 = the constant of the equation and, β i = the coefficient of the predictor variables i. Using the logistic transformation in this way overcomes problems that might arise if p was modeled directory as a linear function of the explanatory variables; in particular it avoids fitted probabilities outside the range (0, 1). The parameters in the model can be estimated by maximum likelihood estimation. The slope coefficient βj associated with an explanatory variable j x represents the change in log odds for an increase of one unit in . j x To assess the significance of the logistic regression coefficients the Wald statistic and likelihood ratio test are used [17]. The Wald statistic takes the form: Where β 0 = the constant of the equation and, β i = the coefficient of the predictor variables i. Using the logistic transformation in this way overcomes problems that might arise if p was modeled directory as a linear function of the explanatory variables; in particular it avoids fitted probabilities outside the range (0, 1). The parameters in the model can be estimated by maximum likelihood estimation. The slope coefficient βj associated with an explanatory variable j x represents the change in log odds for an increase of one unit in . j x To assess the significance of the logistic regression coefficients the Wald statistic and likelihood ratio test are used [17]. The Wald statistic takes the form:  ,where ,where 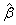 represents the estimated coefficient β and represents the estimated coefficient β and 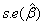 is its standard error. Under the null hypothesis of zero slope and based on asymptotic theory, this quantity follows a chi-square distribution with one degree of freedom. If the estimated value of the slope is small and its estimated variability is large, then we can not conclude that the slope is significantly different from zero and vise versa [17]. is its standard error. Under the null hypothesis of zero slope and based on asymptotic theory, this quantity follows a chi-square distribution with one degree of freedom. If the estimated value of the slope is small and its estimated variability is large, then we can not conclude that the slope is significantly different from zero and vise versa [17]. |
| |
The likelihood ratio test for overall significance of the beta's coefficients for the independent variables in the model is used [21,22]. The test based on the statistic "G" under the null hypothesis that the beta's coefficients for the co-variates in the model are equal to zero. G statistic takes the form:  |
| |
| The distribution of "G" is a chi-square with q degree-of-freedom, where q is the number of covariates in the logistic regression equation. Hauck and Donner [23] and Jennings [24] examined the performance of the Wald test and found that the test often failed to reject the null hypothesis when the coefficient was significant. They recommended that the likelihood ratio test to be used. The likelihood statistic L is used to asses the fitness of the model. The sampling distribution of the – 2 log L has a chi-square distribution with q degrees of freedom under the null hypothesis that all regression coefficients of the model are zero [24]. A significant p-value provides evidence that at least one of the regression coefficients for an explanatory variable is non zero. Hosmer and Lemeshow [21] developed a goodness-of-fit test for logistic regression models with binary responses. They proposed grouping based on the value of the estimated probabilities. This test is obtained by calculating the Pearson chi-square statistic from the 2×g table of observed and expected frequencies, where g is the number of groups. |
| |
The statistic is written 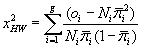 where;Ni is the number of observation in the ith group, oi is the number of event outcomes in the ith group, where;Ni is the number of observation in the ith group, oi is the number of event outcomes in the ith group,  is the average estimated probability of an event outcome for the ith group. The Hosmer and Lemeshow statistic is then compared to a chi-square distribution with (g – 2) degree of freedom. However, Christensen [25] gave the following warnings about the Hosmer and Lemeshow goodness-of-fit test; is the average estimated probability of an event outcome for the ith group. The Hosmer and Lemeshow statistic is then compared to a chi-square distribution with (g – 2) degree of freedom. However, Christensen [25] gave the following warnings about the Hosmer and Lemeshow goodness-of-fit test; |
| |
| 1. If too few groups are used to calculate the statistic (<5) it will always indicate that the model fits the data. That is why Hosmer and Lemeshow [21] advocated that, before finally accepting that a model fits; an analysis of the individual residuals and relevant diagnostic statistics is performed (pp.151-156). |
| |
| 2. It is highly dependent on how the observations are grouped. |
| |
| 3. It is a conservative test. |
| |
| 4. It has low power to detect specific types of lack of fit (such as nonlinearity in an explanatory variable). |
| |
| The odds ratio |
| |
The odds ratio is a measure of association for 2×2 contingency table [26]. In 2×2 tables the probability of "success" is 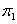 in row 1 and in row 1 and 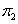 in row 2. Within row 1, the odds of success are defined to be: in row 2. Within row 1, the odds of success are defined to be: 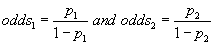 |
| |
Evaritt [18] and Agresti [27] define the odds ratio in two groups of subjects as "the ratio of odds". Thus;  . For the binary regression model, the odd ratio is the exponent . For the binary regression model, the odd ratio is the exponent 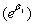 is the ratio of odds for a one-unit change in is the ratio of odds for a one-unit change in  [21]. The change in Log odds, and the corresponding change in the odds ratio, for a,c units is estimated [21]. The change in Log odds, and the corresponding change in the odds ratio, for a,c units is estimated  . When the two groups of odds are identical then the odds ratio is equal to one. The corresponding lower and upper confidence limits for odds ratio for a c units change are . When the two groups of odds are identical then the odds ratio is equal to one. The corresponding lower and upper confidence limits for odds ratio for a c units change are 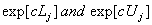 , respectively, for (c>0), , respectively, for (c>0),  respectively, for (c<0), where respectively, for (c<0), where 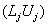 ; can be either the likelihood ratio-based confidence interval or the Wald confidence interval for jβ [27,29]. ; can be either the likelihood ratio-based confidence interval or the Wald confidence interval for jβ [27,29]. |
| |
| Cross validation techniques |
| |
| Cross - validation is a general procedure used in statistical model building. It can be used to decide on the order of a statistical model including time series models, regression models, mixture distribution models, and discrimination models [30]. Cross validation is performed in different ways, some of them are: |
| |
| 1. Take two random subsets of the data. Models are fit or various statistical procedures are applied to the first subset and then are tested on the second subset. |
| |
| 2. Leave - one – out technique is performed by fitting to all but one observation and then testing on the remaining one and has also been called "cross - validation by Efron [31]”, but it does not provide an adequate test. |
| |
| 3. Fit the model n times, each time leaving out a different observation and testing the model on estimating or predicting the observation left out each time. This provides a fair test by always testing an observations not used in the fit. It also is efficient in the use of the data for fitting the model since n − 1 observation is always used in the fit. Hit ratio is the percentage of objects (individuals, respondents, firms, etc.) correctly classified by the logistic regression model. It is calculated as the number of objects in the diagonal of the classification matrix (Ho) divided by the total number of objects (N). Also known as the Percentage correctly classified [32]. |
| |
This can be compared with the maximum chance and proportional chance criterion to determine the discriminating power of the function. Maximum chance criterion is the percentage of the total sample represented by the larger of the two groups. The proportional chance criterion is obtained from the actual occurrence of second cancer by the equation 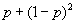 , where p = proportion of individuals in group (having a second cancer) and 1-p = proportion of individuals in group (not having a second cancer). According to Marcoulides [33] the difference between , where p = proportion of individuals in group (having a second cancer) and 1-p = proportion of individuals in group (not having a second cancer). According to Marcoulides [33] the difference between  may be tested by the following statistic may be tested by the following statistic  Where the significance of z is found by comparison with a critical value from a standard normal distribution. Where the significance of z is found by comparison with a critical value from a standard normal distribution. |
| |
| Classification accuracy: The ROC curve |
| |
| ROC (Receiver Operating Characteristic) analysis is being used as a method for evaluation and comparison of classifiers [34]. The ROC gives complete description of classification accuracy as given by the area under the ROC curve. The ROC curve originates from signal detection theory [21]; the curve shows how the receiver operates the existence of signal in the presence of noise. The ROC curve plots the probability of detecting true signal (sensitivity) and false signal (1 – specificity) for an entire range of possible cut points. The sensitivity and specificity of a classifier also depend on the definition of the cut-off point for the probability of predicted classes. In many situations, not all misclassifications have the same consequences, and misclassification costs have to be taken into account. A ROC curve demonstrates the trade-off between true positive rate and false positive rate in binary classification problems. To draw a ROC curve, the True Positive Rate (TPR) and the False Positive Rate (FPR) are needed. |
| |
| âÞ£ TPR determines the performance of a classifier or a diagnostic test in classifying positive cases correctly among all positive samples available during the test. |
| |
| âÞ£ FPR, on the other hand, defines how many incorrect positive results, which are actually negative, there are among all negative samples available during the test. |
| âÞ£ Because TPR is equivalent to sensitivity and FPR is equal to (1 –specificity), the ROC graph is sometimes called the sensitivity vs. (1 - specificity) plot. |
| |
| The area under the ROC curve has become a particularly important measure for evaluating classifiers’ performance because it is the average sensitivity over all possible specificities [35]. The larger the area, the better the classifier performs. If the area is 1.0, the classifier achieves both 100% sensitivity and 100% specificity. If the area is 0.5, then we have 50% sensitivity and 50% specificity, which is no better than flipping a coin. This single criterion can be compared for measuring the performance of different classifiers analyzing a dataset [36,37]. |
| |
| After a classifier has been made, it is also useful to measure its calibration. Calibration evaluates the degree of correspondence between the estimated probabilities of a specific outcome resulting from a classifier and the outcomes predicted by domain experts. This can then be tested using goodness-of-fit statistics. This test examines the difference between the observed frequency and the expected frequency for groups of patients and can be used to determine if the classifier provides a good fit for the data. If the p-value is large, then the classifier is well calibrated and fits the data well. If the p-value is small, then the classifier is not well calibrated. |
| |
| Statistical Analysis and Results |
| |
| Data used for the analysis comprised of 1500 registered patients in Ain Shams University Hospitals, Cairo, Egypt, by different stages of cancer in 2006; 200 patients met the study assumptions were classified as: |
| |
| 1. Has a first primary cancer stage I. |
| |
| 2. Has at least one year free cancer after first cancer treatment. |
| |
| |
| The dependent variable used in the study was the classification variable (0 for those not has a second primary cancer, 1 for those who has a second primary cancer), explanatory variables used in this study were: age at first cancer occurrence, gender( male-female), marital status( married –single), area ( urban or rural), radiation treatment of first cancer(yes- no) ,family history of cancer (yes, no), smoking ( yesno), Obesity before first cancer (yes-no), and education ( Yes-no) for patients above 18 or parents for patients less than 18 . SPSS software package is used for the analysis. The maximum likelihood method is used to estimate the coefficient and its standard error in addition the Newton-Raphson method to solve the nonlinear equations for the logistic model maximum likelihood estimations, Table 1 shows the SPSS output. |
| |
|
|
Table 1: The estimated coefficient, its S.E and Wald test. |
|
| |
| At the 0.05 level of significant, Table 1 shows that " Education" ," Smoking", " Treatment by radiation", " family history", and " marital status" were highly significant. The coefficients estimate is used to estimate the probability of the second cancer occurrence [38] as follows: |
| |
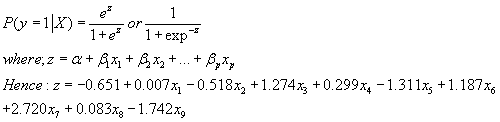 |
| |
| The sign of the coefficients of the estimated logistic function in Table 1 above gives an explanation of the explanatory variables used, as given in Table 2. |
| |
|
|
Table 2: The sign analysis. |
|
| |
| The odds ratio results |
| |
| The following odds ratios were calculated using the formula; |
| |
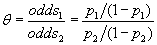 |
| |
| For every covariate used in the study, results are given in Table 3. |
| |
| From Table 3, it is evident that patients who smoke, patients with family history and married persons are highly susceptible for a second cancer occurrence. |
| |
|
|
Table 3: Odds Ratios and 95% Confidence Intervals for Covariates. |
|
| |
| Table 4 gives the classification table. Using the obtained Z function observations are classified as follows, using a prior probability of 0.50 |
| |
|
|
Table 4: Classification Table. |
|
| |
| From Table 4, we conclude that; |
| |
| A .80% of all patients not have a second cancer are correctly classified, and 20% are incorrectly classified. |
| |
| B.68% from all patients who have a second cancer are correctly classified, 32% are incorrectly classified. |
| |
| C. The overall correct percentage was 74%, which reflects the model's overall explanatory strength. |
| |
| Model assessment |
| |
| The -2 log likelihood for the constant only model obtain by fitting the constant only model was 277.259;and the -2 log likelihood for the overall model was 194.585. Thus the value of the likelihood ratio test is; G = 277.259 −194.585 = 82.674 . |
| |
And the p-value for the test is 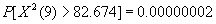 which is highly significant at theα < 0.001level. The null hypothesis is rejected and we conclude that at least one and perhaps all beta's coefficient are different from zero. The likelihood ratio tests for all covariates and for each covariate are given in Table 5. which is highly significant at theα < 0.001level. The null hypothesis is rejected and we conclude that at least one and perhaps all beta's coefficient are different from zero. The likelihood ratio tests for all covariates and for each covariate are given in Table 5. |
| |
|
|
Table 5: Likelihood ratio test. |
|
| |
From table 5 we note that the covariates (family history, smoking, education, treatment by radiation and marital status) are statistically significant; while the covariates (gender, age at first cancer, area and obesity) are statistically non-significant. The Wald test is obtained by comparing the maximum likelihood estimate of the beta's, 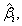 to its standard error. The resulting ratio, under the hypothesis that β = 0 i are given in Table 5. It is evident that the covariates (family history, smoking, education, treatment by radiation and marital status) are statistically significant; while the covariates (gender, age at first cancer, area and obesity) are statistically not-significant.Stepwise logistic regression analysis is used to reduce number of covariates. results are summarized the results as in table 6. to its standard error. The resulting ratio, under the hypothesis that β = 0 i are given in Table 5. It is evident that the covariates (family history, smoking, education, treatment by radiation and marital status) are statistically significant; while the covariates (gender, age at first cancer, area and obesity) are statistically not-significant.Stepwise logistic regression analysis is used to reduce number of covariates. results are summarized the results as in table 6. |
| |
|
|
Table 6: Step-wise Binary Logistic Regression Results. |
|
| |
| And the logit is: |
| |
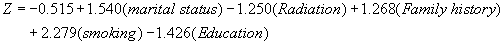 |
| |
| The Logit (Z) above indicates that: married patients are more susceptible to develop a second cancer; treatment by radiation decreases the susceptibility; a patient with family history is more susceptible to develop second cancer; smokers are more susceptible than nonsmokers, and educated patients are less susceptible to develop a second cancer. The exponent (Exp (B)) in Table 6 is the odds ratio, thus: |
| |
| 1. The odds for married patients to single patients to develop second cancer are 4.667. |
| |
| 2. The odds for patients with family history to patients with no family history to develop second cancer are 3.55. |
| |
| 3. The odds for smokers to nonsmokers to develop second cancer are 9.76. |
| |
| Table 7 gives the classification table. Using the obtained Z function observations are classified as follows, using a prior probability of 0.50. |
| |
|
|
Table 7: Classification Table. |
|
| |
| a. 82% of all patients not have a second cancer are correctly classified, and 20% are incorrectly classified. |
| |
| b. 67% from all patients who have a second cancer are correctly classified, 32% are incorrectly classified. |
| |
| c. The overall correct percentage was 74.5%, which reflects the model's overall explanatory strength. |
| |
| The value of the Hosmer – Lemeshow goodness-of-fit statistic computed for the full model was C = 4.060 and the corresponding p-value computed from the chi-square distribution with 8 degree of freedom is 0.852 this indicates that the model seems to fit quite well. |
| |
| Cross validation results |
| |
| Using Efron [31] leave-one-out Cross Validation goodness-of-fit statistic the results for the full model was (using prior probability of 0.50) summarized in Table 8. |
| |
|
|
Table 8: Cross validation Result. |
|
| |
| The classification matrix shows the accuracy of second cancer occurrence prediction in the cross validation leave-one-out sample as presented in Table 8 above. In this sample of 200 patients, actual occurrence of second cancer was 50%. Of the 100 patients that 67 or 67% were correctly classified into group having a second cancer. Of the 100 patient that not having a second cancer, 78 or 78% were correctly classified into group not having a second cancer. The total correctly classified was 145 of 200 or 72.5%. The maximum chance Criterion is 50% and the proportional chance criterion is 50% also. Because the percentage correctly classified was 72.5% (22.5% greater than proportional chance), Z test evident that difference are statistically significant (p-value <0.001). Using ROC curve for the classification accuracy, it is found that the area under the ROC curve, which ranges from zero to one, provides a measure of the model's ability to discriminate between those subjects who experience the response of interest versus those who do not. Plotting sensitivity versus (1 – specificity) over all possible cut-points is shown in the Figure below (Figure 1). The area under the ROC curve for the full model was is 0.843 this is considered excellent discrimination |
| |
|
|
| |
| Summary and Conclusions |
| |
| In this study, social-demographic risk factors of developing a second primary cancer using logistic regression model were studied. The social-demographic risk factors used are age at first cancer, gender, area the patient live in, marital status, family history, smoking, education and obesity in addition to treatment by radiation. The binary logistic regression model is used to estimate the probability of having second primary cancer. Significance testing for the logistic coefficients using Wald test and likelihood ratio show that smoking, family history, marital status, and education are the significant factors. The odds ratio for each covariate compare whether the probability of having a second primary cancer is the same for each covariate groups. The odds ratio for smokers to non-smokers ranges between 3 times to 65 times with confidence 95%. To assess the fitness of the model the maximum likelihood test and Hosmer and Lemeshow test are used. The logistic regression model proved to have a lower sensitivity level due to some other clinical risk factors not considered in this study. The study concludes that: married patients are more susceptible to develop a second cancer; treatment by radiation decreases the susceptibility; a patient with family history is more susceptible to develop second cancer; smokers are more susceptible than non-smokers, and educated patients are less susceptible to develop a second cancer. |
| |
| The researcher recommends the following: |
| |
| 1. Replicate the same study with an increased sample size. |
| |
| 2. Develop a logistic regression model that contains repeated measures. |
| |
| 3. Replicate the same study to include repeated measures on the same patients, especially when some demographic factors change, and age develops. |
| |
| 4. Use the reached significant factors and add more clinical risk factors which were not available at the hospitals records when the research was conducted. |
| |
| 5. Apply Classification and Regression Tree (CART) and compare the results with the binary logistic regression model. |
| |
| |
| References |
| |
- DeVita VT, Hellman S, Rosenberg SA (2008) Cancer: Principles and practice of oncology. 8th Ed, vol. 6, wolters kluwer, lippincott Williams & wilkins.
- Ingles CJ, Garcia-Fernandez JM, Castejon JL, Valle Antonio BD, Marzo JC (2009) Reliability and validity evidence of scores on the Achievement Goal Tendencies Questionnaire in a sample of Spanish students of compulsory secondary education. Psychology in the Schools, Wiley Periodicals, Inc., A Wiley Company 46: 1048-1060.
- King G, Zeng L (2002) Estimating risk and rate levels, ratios and differences in case-control studies. Stat Med 21: 1409-1427.
- Saijo Y, Ueno T, Hashimoto Y (2008) Twenty-four-hour shift work, depressive symptoms, and job dissatisfaction among Japanese firefighters. Am J Ind Med 51: 380-391.
- Garcia-Ramirez M, Martinez MFM, Balcazar FE, Suarez-Balcazar Y, Albar M, et al. (2005) Psychosocial empowerment and social support factors associated with the employment status of immigrant welfare recipients. J Community Psychol 33: 673-690.
- Neagu R, Hoerl R (2005) A Six Sigma Approach to Predicting Corporate Defaults. Quality and Reliability Engineering International. 21: 293-309.
- Kleijnen M, De Ruyter K, Wetzels M (2004) Consumer adoption of wireless services: Discovering the rules, while playing the game. Journal of Interactive Marketing, Wiley Periodicals, Inc., A Wiley Company, and Direct Marketing Educational Foundation, Inc 18: 51-61.
- Barone S, Lombardo A, Tarantino P (2007) A weighted logistic regression for conjoint analysis and Kansei engineering. Quality and Reliability Engineering International 23: 689-706.
- Sallis JE, Deo Sharma D (2009) Knowledge seeking in going abroad. Thunderbird International Business Review. 51: 441-456.
- Kirkos E, Spathis C, Manolopoulos Y (2009) Audit-firm group appointment: an artificial intelligence approach. Article on line in advance of print, Intelligent Systems in Accounting, Finance & Management, John Wiley & Sons, Ltd.
- Erhart M, Hagquist C, Auquier P, Rajmil L, Power M, et al. (2009) A comparison of Rasch item-fit and Cronbach's alpha item reduction analysis for the development of a Quality of Life scale for children and adolescents. Child Care Health Dev Blackwell Publishing Ltd.
- O'Leary DE (2009) Downloads and citations in Intelligent Systems in Accounting. Finance and Management. International Journal of Intelligent Systems in Accounting, Finance & Management 16: 21-31.
- Weber SO, Scholz RW, Michalik GW (2008) Incorporating sustainability criteria into credit risk management. Business Strategy and the Environment 19: 39-50.
- Sanchez LA, Lana AB, Hidalgo AA, Rodriguez MJC, Del Valle MD, et al. (2008) Risk factors for second primary tumours in breast cancer survivors. Eur J Cancer Prev 17: 406-413.
- Kaufman EL, Jacobson JS, Hershman DL, Desai M, Neugut AI (2008) Effect of Breast Cancer Radiotherapy and Cigarette Smoking on Risk of Second Primary Lung Cancer. J Clin Oncol 26: 392-398.
- Rubino C, De Vathaire F, Shamsaldin A, Labbe M, Le MG (2003) Radiation dose, chemotherapy, hormonal treatment and risk of second cancer after breast cancer treatment. Br J Cancer 89: 840–846.
- Afifi A, Clark VA, May S (2004) Computer- Aided Multivariate Analysis. Fourth Edition, Champman and Hall/CRC.
- Everitt BS (1998) The Cambridge Dictionary of Statistics. Cambridge University Press.
- Evans M, Hastings N, Peacock B (1993) Statistical Distributions. Second Edition, Wiley, New York.
- Altman DG (1991) Practical statistics for medical research. Champman and Hall, London.
- Hosmer DW, Lemeshow S (2000) Applied Logistic Regression, Second Edition, Wiley, Inc., New York.
- Fienberg SE (1980) The analysis of cross-classified categorical data. Second Edition, The MIT Press, Cambridge, Massachusetts.
- Hauck WW, Donner A (1977) Wlad's test as applied to hypotheses in logit analysis. J Am Stat Assoc 72: 851-853.
- Jennings DE (1986a) Judging inference adequacy in logistic regression. J Am Stat Assoc 81: 471-476.
- Christensen R (1997) Log-Linear models and logistic regression. Second Edition. Springer-verlag. New York.
- Agresti A (2007) An Introduction to Categorical Data Analysis. Second Edition, Wiley, Inc., New York.
- Agresti A (2002) Categorical Data Analysis. Second Edition, Wiley, Inc., New York.
- Fleiss JL (1981) Statistical Methods For Rates And Proportions. Second Edition. John Wiley & Sons, Inc.
- The SAS System (1995) Logistic regression examples using the SAS system. Version 6, First Edition. SAS institute Inc., Cary. NC, USA.
- Chernick MR (2008) Bootstrap Methods: A Guide for Practitioners and Researchers. Second Edition, Wiley, Inc., New York.
- Efron B (1983) Estimating the error rate of a prediction rule: improvements on cross validation. J Am Stat Assoc 78: 316-331.
- Hair JF, Anderson RE, Babin BJ, Black WC (2009) Multivariate Data Analysis. Seventh Edition. Maxwell Macmillan International, New York.
- Marcoulides GA, Hershberger LS (1997) Multivariate statistical methods: A first course. Lawrence Erlbaum Associates, Mahwah, New Jersey.
- Ferri C, Flach P, Hernandez-Orallo J (2002) Learning Decision Trees Using the Area under the ROC Curve. Nineteenth International Conference on Machine Learning (ICML 2002); Morgan Kaufmann 46-139.
- Bradley AP (1997) The use of the area under the roc curve in the evaluation of machine learning algorithms. Pattern Recognition 30: 1145-1159.
- Hanley JA, McNeil BJ (1982) The meaning and the use of the Area under a receiver operating characteristic (ROC) curve. Radiology 143: 29-36.
- Bamber D (1975) The area above the ordinal dominance graph and the area below the receiver operating characteristic graph. J Math Psychol 12: 387-415.
- Ashour S, Abo Elfotouh S (2005) Presentation and statistical analysis using SPSSWIN. Second Part, Advanced Applied Statistics, Institute of Statistical Studies and Research. Cairo University, Egypt (in Arabic).
|
| |
| |
