Online Diagnosis-Treatment Department Recommendation based on Machine Learning in China
Received: 26-Sep-2022 / Manuscript No. DPO-22-75917 / Editor assigned: 28-Sep-2022 / PreQC No. DPO-22-75917 / Reviewed: 12-Oct-2022 / QC No. DPO-22-75917 / Revised: 19-Oct-2022 / Accepted Date: 19-Oct-2022 / Published Date: 28-Oct-2022 DOI: 10.4172/ 2476-2024.7.S12.001
Abstract
Objective: At present, the HPV DNA test is used to triage young female patients with abnormal cytology. Still, it is not suitable to precisely identify the population with persistent HPV infection. The purpose of this study was to evaluate the diagnostic value of HPV E6/E7 mRNA test in young women with abnormal cytology by comparing HPV DNA test.
Methods: A total of 258 young women aged 20 to 29 years, with squamous cell abnormalities on the cervical cytology, were enrolled in this study between January 2015 and December 2019.All patients were subject to HPV DNA test, HPV E6/E7 mRNA test, colposcopy biopsy, and histopathological examination. A comparative analysis of the diagnostic performance of the HPV DNA test and HPV E6/E7 mRNA test was conducted according to the histological diagnosis (CIN II and CIN II+ were defined as high-grade squamous intraepithelial lesion+ (HSIL+)).
Results: The results showed that HPV E6/E7 mRNA test had a higher specificity of 47.3% (40.0%-55.1%) for HSIL+ compared to HPV DNA test that had specificity of 16.0% (11.0%-22.6%)in young women(P<0.01). The HPV E6/E7 mRNA test presented high rates of specificity, positive predictive value (PPV), and negative predictive value(NPV), which were 92.1%(86.0%-96.0%), 62.1%(42.4%-78.7%), 92.1%(85.9%-95.8%), respectively, compared to that of HPV DNA, which were 15.8%(10.4%-23.2%),14.6%(9.40%-21.9%), and 71.0%(51.8%-85.1%),respective ly(P<0.01)in young women with mildly abnormal cytology (ASC-US and LSIL). Yet, with severe abnormal cytology (ASC-H and HSIL), HR-HPV test was similar to HPV E6/E7 mRNA test in sensitivity(χ2=0.98, P=0.322), specificity (χ2=0.938, P=0.333), PPV(χ2=0.074, P=0.786) and NPV (χ2=0.00, P=1.000).
Conclusions: Compared to the HPV DNA test, the HPV E6/E7 mRNA test has better clinical value in screening cervical cancer and predicting the risk of HSIL+ in young women, especially those with mild abnormal cytology.
Keywords: Online diagnosis-treatment; Recommendation system;Machine learning; Data mining; Secondary department
Introduction
According to the 41st China Statistical Report on Internet Development issued in January 2018, China’s online medical service has achieved rapid development [1]. With the trend of applying internet in healthcare, online mode of diagnosis-treatment service is becoming more and more popular. As a supplement to the traditional medical service mode, online medical mode provides services of online appointment, online consultation, online remote treatment, etc. As an important medium for doctor-patient online communication and consultation, online diagnosis-treatment platforms integrate experts and doctors of various fields all over the country. Using the online platform, patients are able to choose real doctors or experts according to their specific conditions, and communicate with them whenever and wherever by ways of texts, pictures, and etc. Through interactive communications of doctors-patient’s Q&A’s, doctors would have a preliminary diagnosis and then provide patients with services such as telling medical knowledge, making diagnosis, as well as giving diagnosis-treatment advices.
The existing researches on department recommendation are mainly in the following situations: The main aspects are based on expert system and department recommendation based on similarity calculation: The former mainly realizes the purpose of department recommendation by establishing a medical knowledge base with the help of medical experts and based on fuzzy logic RBF neural network, The medical knowledge base emphasizes the use of rule-based reasoning engines to simulate the reasoning process of medical experts and determine the possible diseases of patients, so as to achieve the patient’s target department recommendation. The above methods effectively improve the accuracy of department recommendation [2,3]. However, there are problems such as low computational efficiency and high maintenance cost of knowledge base due to many inference rules; The TF-IDF algorithm [4-6]. The combination of the centre of gravity backward shift and the medical professional corpus, etc., can calculate the possibility of disease and the possible corresponding symptom words of patients to achieve the purpose of department recommendation [7].
The traditional medical field recommendation algorithm mainly has the following problems: 1) Department recommendation field: The recommendation based on expert system has problems such as explosion of knowledge rule inference and high maintenance cost of knowledge base; department recommendation based on similarity cannot effectively identify synonyms, which may It will lead to a decrease in the recommendation accuracy. 2) Although related literatures have found that collaborative filtering can reduce the problem of data sparsity [5-8], it still cannot completely avoid the performance problems caused by data sparsity.
Offline hospitals usually set up reception desk for medical consultation, guiding patients to choose outpatient departments. Yet, this kind of service is not suitable for online diagnosis-treatment services because it would increase platform’s operating cost and reduce platform’s timeliness and convenience. Therefore, before using online diagnosis-treatment service, patients need to choose a doctor in a certain department according to their own judgment of the condition. However, most patients do not understand or even completely do not have any idea of medical expertise, leading to a lack of a comprehensive understanding of their own conditions. When choosing departments and doctors online independently, patients are prone to wrong department registration and wrong doctors. According to a report released by a big data research institution in 2019, by the end of 2018, the number of users in China’s medical and healthcare market was about 800 million [9]. Thanks to a large number of doctor-patient communication online, the online health communities have accumulated a large amount of real consultation data for academic research. Nowadays, analysing massive online diagnosis-treatment data and optimizing the effect of online department recommendation for patients have become not only hotspots but also difficult issues. Machine learning has been widely and successfully applied in medical fields such as epidemic disease prediction, auxiliary clinical diagnosis, identification of adverse drug reactions, and medical expense management [10-13]. Hence, this study applies machine learning technology to intelligent department recommendation for online diagnosis-treatment services, with the purpose of recommending appropriate departments for patients according to the consultation text entered by patients online
Based on more than 50,000 pieces of real online doctor-patient Q&A data from WeDoctor platform, this study compares accuracy rate of various models for intelligent recommendation of departments. To be specific, the study transforms the comparison task into binary questions. Then, following the hierarchical order of departments and secondary departments, patient’s questions online are classified layer-by-layer. By constructing a variety of classification models, the appropriate departments can be recommended according to data of similar cases. After identifying the optimal classification model by comparing the models’ recommendation accuracy, in-depth analysis is further conducted and directions as how to improve the effect of intelligent recommendation are proposed, providing reference for online diagnosis-treatment platform. By optimizing online medical services, improve patient satisfaction, and further promote patients to continue to use the online medical community.
Literature Review
User behavior at diagnosis-treatment platform online
User behavior typical of online diagnosis-treatment platform is various. The current literature mainly focuses on users’ information disclosure, information acquisition and searching, information sharing, information service usage and continuous usage, as well as social support behavior.
In terms of methods, questionnaire surveys and user interviews are the most important traditional approaches [14]. Yet, considering that questionnaire data is subjective in nature and limited in quantity, the need for objective data from the network of the online health community is increasing for research of user behaviours on these health communities and diagnosis-treatment platforms. For instance, the impact of user competition on health status was explored in the context of an online weight-loss community [15].
With regard to obtaining objective data, web crawler is frequently utilized. For instance, web-based data from GoodDoctor online health community was obtained using a web crawler, and multiple regression analysis was then conducted to examine the impact of doctors’ and patients’ behavior on knowledge exchange [16].
With regard to analyzing objective network data, techniques such as text mining and content analysis have been applied, enriching research methods used to study user behavior in online health communities. For instance, by applying text mining technique, users’ question data can be captured based on the keyword hypertension and then analyzed. The literature found that the informational needs of users in a hypertension health community were concentrated on daily disease management, disease diagnosis-treatment, and expectation to receive emotional support from society [17]. Moreover, another study applied content analysis to subdivide cancer-themed group behaviors on QQ social media platform into six subtypes and make analysis correspondingly. The results showed that the most important types of behavior were emotional support, knowledge sharing and off-topic behavior [18].
Doctor-patient interaction and patients’ trust
Large amount of literature has indicated that doctors are among the most important participant in online health communities. With that in mind, due to information asymmetry existing in online health communities, doctor’s personal information, their responses to patients’ consultations and their electronic word-of-mouth reputation would particularly help patients differentiate doctors at different professional levels to make efficient and effective decisions regarding seeing doctors. For instance, the literature found that a doctor’s electronic word-of- mouth reputation, degree of efforts, and service price significantly influence the quantity of their medical inquiry, and the relationship between reputation and inquiry quantity is partially mediated by service price [19]. Moreover, for different diseases, the influencing factors of doctor’s contribution behavior exert varying degrees of impact within different time lengths [20].
Concerning doctor-patient interactions, existing researches have been mainly carried out from the perspectives of knowledge exchange, doctor-patient communication, and doctor-patient trust. As for perspective of knowledge exchange, the influence of behaviors of both doctors and patients (i.e. amount of knowledge exchanged, trust, cost, benefits, etc.) on effectiveness of knowledge exchange was empirically verified [21]. As for perspective of doctor-patient communication, there is literature that studied doctor-patient interactions from the aspects of doctors’ degree of activity, patients’ visit frequency and satisfaction [17]. As for perspective of doctor-patient trust, based on the conceptual framework of web-based trust, trust factors are usually integrated with perceived benefit and perceived risk to explore influencing factors of doctor-patient trust regarding online health services [22].
Trust is considered to be a basic factor in building successful relationships [23]. Recent studies have focused on the relationship between trust towards providers of products and services and customers’ online purchase intention [24]. Across various contexts, patients’ trust can be defined as patients’ belief and expectation that a medical service provider will take actions beneficial to them when they lack the capability to supervise doctors [25]. The literature has found that trust toward members would impact individuals’ web-based participation behavior, such as seeking and providing information in focus groups [26]. Specifically, hospital rules and regulations as well as doctor’s professional skills and service attitudes will affect patients’ trust in the context of medical organization, medical staff and medical treatment [27]. At the same time, patients’ trust will also affect their own health [28]. In particular, information obtained from credible sources is often considered to be more useful and is regarded as the basis for decision-making [29].
To sum up, it can be found that literature on users in online health communities mainly focus on users’ relationship networks, users’ behavior regarding health information, doctor-patient interactions and patients’ trust, etc. Additionally, the current literature has also addressed the subjects of methods for calculating similarity among virtual health community users, users’ emotional expression in online health communities, member’s value co-creation model and its influencing factors, as well as algorithms of sentiment analysis for users’ online reviews [30-33].
Text mining and classification study regarding online diagnosis-treatment
With the gradual popularization and promotion of online medical treatment, the online medical community that breaks through the limitations of time and space has accumulated a large amount of information on doctor-patient diagnosis and treatment by providing online consultation, consultation and other services, and the resident doctors can give patients time to fully express their demands. The medical service model is favored by the patient group. In the online medical community, patients can provide experience based on their own applications. The text information of such patients may reveal the motivation of users to participate in community behavior, which is conducive to optimizing patient management and recommending information with similar needs to other patient groups. As a supplement to my country’s offline medical service model, online medical communities have unique characteristics in my country that are different from foreign online medical communities. In recent years, the research on recommendation systems in online medical communities has attracted extensive attention of scholars, and recommendation research mainly focuses on online department or doctor recommendation model research. Based on the social support theory, Wu Jiang and Hou Shaoxin analyzed the participation behavior of patients in the online medical community by using the texts of online users in the diabetes community. The research method adopts the LDA (Latent Dirichlet Allocation) model for feature extraction, and the binary classification method to classify user texts and effectively identify patient roles [34].
At present, the recommendation system as a whole is faced with the problem of continuous optimization to improve the recommendation accuracy and user satisfaction. The emergence of knowledge graphs provides a new perspective for the improvement of online recommendation systems. In-depth analysis of the advantages of knowledge graphs in the research of online medical community recommendation systems can limit the effect of scenario-based information recommendation. Shanshan and Pan proposed a scenario- differentiated comprehensive information recommendation model based on the perspective of online medical community information recommendation that integrates knowledge maps and disease profiles. The results show that the information recommendation system with differentiated conditions can more accurately provide assistance for online patient decision-making, reason and output relevant medical knowledge information according to different scenarios, which can effectively meet the online personalized needs of patients [35].
Regarding the need of content analysis for patients’ consultation texts from online diagnosis-treatment platform, some scholars have used natural language processing methods to carry out relevant researches. For instance, the literature integrated LDA-themed model and machine learning algorithm to build a patient text mining process based upon social support theory, exploring types of social support at online diagnosis-treatment platform and then revealing patients’ behavior as a result [36,37]. What’s more, the lexical accuracy co- occurrence network is also used to represent medical domain knowledge to evaluate accuracy of doctor’s online response effectively, and then signal propagation algorithm can be utilized to calculate similarity between actual response and standard response. A large amount of text data will be generated in the process of TCM-patient interaction in the online medical community. This type of data is poorly standardized, sparse, and large in volume. How to efficiently use online data for in-depth mining, fully analyse the needs and preferences of patients, and provide patients with high-quality data and personalized online medical services. With the development of information technology and the deepening of research, deep learning has been fully applied in text information mining and relation extraction in online medical communities. Deep learning models such as Bidirectional Long Short- Term Memory Neural Network (BiLSTM), Conditional Random Field (CRF), Bidirectional Gated Recurrent Unit (BiGRU), etc., have good application results in intelligent recommendation services, knowledge representation, and personalized demand recommendation in online medical communities [38]. Knowledge graph has also been applied in online medical community recommendation research. According to user comment text, keywords are extracted as concept nodes, and the absolute value of keyword co-occurrence similarity reflects the weight between each concept node, making full use of fuzzy cognitive graph analysis Prediction function for online patient disease knowledge recommendation [39].
Regarding classification of patients’ online diagnosis-treatment texts, the literature mainly takes the perspectives of doctors and patients. For example, in order to help doctors to select contents that are of their own domain from a large number of patients’ consultation data, principal component analysis and singular value decomposition were used first for data dimension reduction, dividing platform users into two dimensions and thirty-eight categories, and then regression model was trained to achieve the classification purpose [40-44]. At present, machine learning has been widely applied in fields of data mining, natural language processing, image recognition, recommendation, etc [45-48]. Machine learning can effectively explore nonlinear relationship between users and projects, encode more complex abstractions into higher-level data representation, and capture complex internal relationship within the data itself from a large number of accessible text and visual information data sources [49]. Particularly, the neural network in machine learning technique can learn not only the latent feature representation, but also the complex nonlinear interaction features, so as to achieve better recommendation effect through in- depth analysis of user preferences [50].
Sentiment analysis, text classification and topic extraction are important research directions in natural language processing, text mining and machine learning [51]. Among them, sentiment analysis is mainly to identify subjective information in a text set, such as attitudes, thoughts, opinions or judgments on a specific topic. The existing literature found that feature selection is an important task for efficient classification models, and an effective feature subset can be obtained by aggregating feature-based ensemble filter methods of different feature selection methods [52]. At the same time, sentiment analysis based on deep learning has gradually become a research trend. Through the evaluation of the traditional deep neural network architecture with multiple weighting functions, it is found that the architecture that combines the TF-IDF weighted Glove word embedding and the CNN- LSTM architecture Outperforms traditional deep learning methods [53]. Some scholars have established an effective teacher evaluation and comment sentiment classification method by pursuing the paradigm of deep learning, and searched for a classification method with higher predictive performance based on multi-layer nonlinear information processing. Empirical analysis found that online sentiment classification based on deep learning plus purchase has a classification accuracy rate of 98.29% based on Recurrent Neural Network (RNN) due to traditional machine learning classification [54]. In sentiment analysis, in addition to positive sentiment tendencies, there may also be negative sentiment tendencies. People will use some words to express negative sentiments. As a non-text language, irony will change the sentiment tendencies of text documents to a certain extent. Through a deep learning-based sarcasm recognition method, the feature set based on word embedding and traditional vocabulary, grammar and other feature sets are integrated for experimental analysis [55].
As one of the most challenging tasks in natural language, text classification mining has become an important direction of media data research. The research of acquiring media data by pursuing the paradigm of neural language model and deep neural network found that the accuracy of the results obtained by this model through classification is 95.30% [56]. Different machine learners and ensemble learning methods have been applied. By comparing and analysing different feature schemes, such as author attribution, language features, and discriminative frequency, an ensemble classification scheme integrating random subspace ensemble with random forest is proposed, the highest average prediction rate obtained by this scheme is 94.43%; some scholars have also proposed an effective multi-classification method based on group optimization agent modelling [57]. Experimental results on biomedical text benchmarks show that population-optimized LDA yields better prediction performance compared to conventional LDA. Furthermore, the proposed multi-classifier system outperforms traditional classifier algorithms, ensemble learning and ensemble pruning methods [58]. Applying machine learning to extract keywords as features is widely used in text classification. The experimental results of the research show that Bagging and Random Subspace ensemble methods and correlation-based and consistency-based feature selection methods achieve better results in terms of accuracy, and that combining keyword-based text document representation with ensemble learning can improve Predictive performance and scalability of text classification schemes [59,60].
Class imbalance is an important challenge when applying machine learning, and imbalanced datasets are important in several real-world applications, including medical diagnosis, malware detection, anomaly identification, bankruptcy prediction, and spam filtering. In this paper, we propose a clustering-based under sampling method for consensus imbalance learning. In this scheme, the number of instances in the majority class is under sampled by using a consensus clustering-based scheme. In the empirical analysis, 44 small-scale and 2 large-scale used imbalanced classification benchmarks. For the empirical analysis, in the consensus clustering scheme, the application of five clustering algorithms (i.e., k-means, k-modes, k-means++, self-organizing map and DIANA algorithm) and their combinations are considered. In the classification phase, five supervised learning methods (i.e. Naive Bayes, logistic regression, support vector machines, random forests, and k-nearest neighbors) and three ensemble learning methods (i.e. AdaBoost, bagging, and random subspace algorithms) are applied. The results show that the heterogeneous consensus clustering-based under sampling scheme proposed in this paper yields better prediction performance [61]. In the medical and health field, breast cancer is one of the most common cancers in women. Early diagnosis and treatment of breast cancer can improve the prognosis of patients, so the accuracy of the classification model is required to be higher. Scholars applied machine learning algorithms to construct a three-stage classification model for hybrid intelligent breast cancer diagnosis, and used classification accuracy, sensitivity, specificity, F-measure, area under the curve and Kappa statistic to measure the performance evaluation effect. The results show that the classification accuracy of the model in this paper is as high as 99.7151%, and the classification effect is good [62]. Under today’s fierce competition, the business environment and business system have changed, and the requirements for online information analysis have become higher and higher. As a basic task in bibliometric data analysis, data mining and knowledge discovery, topic extraction is mainly To identify important topics from text collections [63].Some scholars have proposed a two-stage framework for extracting topics for scientific literature research. Combining word embedding with cluster analysis, an improved word embedding scheme and an improved clustering ensemble framework are proposed. Empirical analysis finds that ensemble word embeddings yield better prediction performance compared to baseline word vectors for topic extraction, and that the ensemble clustering framework outperforms baseline clustering methods [64].
To sum up, existing literature regarding online diagnosis-treatment either uses quantitative methods to explore influencing factors of a focal variable, or uses qualitative methods such as questionnaire and content analysis to deeply investigate needs of doctors and patients, as well as patient behavior. Although there are researches using machine learning algorithm for text classification, they mostly discuss algorithm itself, ignoring characteristics of online diagnosis-treatment data. To fill the gap, this study establishes classification model based on subdivision features of departments and following hierarchical classification of departments and secondary departments. With further in-depth analysis of data, this study also examines situations behind the accuracy of the classifier and proposes improvement advices accordingly.
Methodology
Data acquisition and pre-processing
The data comes from WeDoctor platform. This online consultation platform was founded in 2010 and is now one of the largest doctor- patient communicating and assisting platforms in China. As of March 2020, WeDoctor platform has connected more than 7200 hospitals, more than 240000 doctors and more than 200 million users in China. During COVID-19 pandemic, WeDoctor has been providing online counseling, psychological assistance, online referral, medical insurance and popularization of pandemic prevention science to the nation, and as of June of 2020, the cumulative number of visits reached nearly 160 million while the number of free counseling services exceeded 2 million. Specifically, the official website of WeDoctor provides classic doctor-patient online Q&A, covering 11 departments and 20 secondary departments. Each set of Q&A consists of multiple conversations between patients and doctors. To protect privacy, the website automatically hides patients’ gender and age information.
The data in this paper is crawled from the platform, such as patient’s age, gender, geographical location and patient comments and doctor profiles. This kind of information is open to the public and everyone can use computer technology to obtain it on the platform. The information is confidential data in WEI-Yi platform. The platform itself has a sound risk control system, and the data application in this paper are authorized by WEI-Yi platform, and all methods in this paper were carried out in accordance with relevant guidelines and regulations.
When patients use WeDoctor for online diagnosis-treatment, they follow the procedures shown in Figure 1. Before entering the doctor- patient diagnosis-treatment interface, there are two paths to choose. The red arrow represents the path that patients ask questions under the module of multiple doctors responding to one disease. With regard to the question pool, online doctors would choose which question to reply and multiple doctors can respond to one question simultaneously. To the contrary, the green arrow represents the other path that patients first choose the department or doctor of a hospital online. Under this path, if quality information is obtained before patients’ specific diagnosis- treatment at one time, the platform can intelligently recommend appropriate department to them through machine learning. The quality information includes patients’ firstly posted question and their demographic information such as age, gender, etc. Moreover, the logic behind the recommendation effect is the assumption that the actual online consultation department of each patient is consistent with their condition.

Figure 1: The online diagnosis and treatment process of patients on the Weyi platform.
In order to avoid errors caused by differences among departments, all patients’ first question of their online Q&A dialogues covering all 11 departments and 20 secondary departments was crawled, labeling the data with the corresponding department name at the same time. The sample of departments is shown in Table 1.
| Department | Secondary department | Question sample | Sample size |
|---|---|---|---|
| Internal medicine department | Neurology department | The 53-year old is flustered and has difficult to fall asleep | 4065 |
| Endocrinology department | Thirst, dry tongue, hunger, obesity, sweating often | 2092 | |
| Rheumatology and immunology department | Circadian clock disorder accompanied by joint pain all over the body | 3070 | |
| Surgical department | Urology department | Recurrent urinary tract infection | 2825 |
| Breast surgery department | There are small lumps in the breast | 2680 | |
| General surgery department | There are multiple echo areas on both sides of thyroid gland | 6358 | |
| Department of gynecology and obstetrics | Gynecology department | There is a pimple on the lower part of the outer labia near the vaginal opening | 5040 |
| Obstetrics department | Need of blood test for HCG, check cleft lip and palate | 2394 | |
| Department of orthopedics | Spine surgery department | The middle finger of the right hand has been numb for about two weeks | 2562 |
| Joint surgery department | When squatting down, knees feel like they're stuck | 2086 | |
| Traumatic orthopedics department | 86-year old man has festering leg for a long time | 1820 | |
| Department of otolaryngology | E.N.T department | Sleep snoring, snoring pause time interval is relatively long, nasal congestion and dyspnea | 2652 |
| Ophthalmology department | 53-year old, dry eyes, often squeeze eyes, afraid of tears | 1956 | |
| Head and Neck surgery department | 50-year old female has a sore throat under the clavicle on the right side of her neck | 1845 | |
| Department of dermatology | Department of dermatology | Red and itchy thigh root, a little exudation, it will hurt when touched | 4405 |
| Andrology department | Andrology department | There is blood in the semen, which is brown. Had prostatitis history | 2568 |
| Pediatric department | Pediatric department | Baby is more than 4 months old, frequent crying, sleep with nasal congestion | 2382 |
| Psychiatry department | Psychiatry department | A 52-year old female suffered from severe insomnia | 2346 |
| Department of cardiology | Department of cardiology | 80-year old, had brain surgery after stroke 10 year ago, what department should I see? | 1468 |
| Department of stomatology | Department of stomatology | The right side of the gum is swelling and painful, pain is becoming more and more serious, feel pain even when swallowing saliva | 3018 |
| Total | 57632 |
Table 1: Question sample of different departments.
To pre-process data, self-customized medical dictionary was imported; Python’s Jieba word segmentation was used to automatically segment patient’s question texts, removing meaningless stop words such as “of” and “already”. Then, taking “Department-Secondary Department” as the hierarchical basis, 80% of the data of each department was extracted as the training set, leaving the other 20% as the test set.
Department recommendation
Recommendation of first-level departments: For questions input by patients, every keyword for each sentence can be obtained after word segmentation and word-stopping removal. Next, the corresponding question set can be obtained by positioning question sentences that are associated with each keyword. The authors divided the question set into sample dataset and test dataset, both containing information of patients’ condition description text, online pre-diagnosis department recommendation, etc. Then, use the word2vec library to train a word vector model on the keywords of the sentences in the sample data set, calculate the similarity between the questions input by the patient in the test data set and the word vector model of the sample data set, and lastly select the most similar questions to the sample data set in the test dataset. Following the rule that higher similarity indicates the same one department, after screening the similarity calculation one by one, the department with the highest similarity would be the final recommendation result.
Step 1: This module pre-processes the sample dataset using the following code. The aim is to segment words, remove stop-words, and retain key parts or key symptoms with regard to patients’ condition description online.
The code is as the follows:
with open(‘test.txt’) as f:
document=f.read()
document_cut=jieba.cut(document)
result=’ ‘.join(document_cut)
result=result.encode(‘utf-8’)
with open(‘test2.txt’, ‘w’) as f2:
f2.write(result)
f.close()
f2.close()
Step 2: This module used the word2VEC library to train the word vector model of
dermatology on sample data such as “dermatology. XLS”.
The code is as the follows:
logging.basicConfig(format=’%(asctime)s : %(levelname)s : %(message)s’,
level=logging.INFO)
sentences=word2vec.LineSentence(‘test2.txt’)
model=word2vec.Word2Vec(sentences, hs=1,min_ count=1,window=3,size=100)
model.save(u’fuke.model’)
Step 3: The module mainly had two goals to achieve. First, preprocess the test data, including word segmentation, stop-words removal, as well as retaining key parts or symptoms for the disease description. Second, compare the word vectors of test data and that of the training results, and the departments with high similarity were recommended to patients.
The code is as the follows:
#Note: Load the department’s word vector model
model_1=word2vec.Word2Vec.load(‘pifuke.model’)
for strZhengZhuang in symptom word set of a certain patient try:
sim3=model_1.most_similar(strZhengZhuang,topn=20)
if sim3.__len__()>0:
return 1
except:
return 0
#Note: Number of matching words/total number of symptom words for a patient=
Matching probability
probability=Words/WordsCount
Recommendation of second-level departments: On the basis of the previous step, an online diagnosis and treatment department recommendation model based on support-vector machine, multinomial naive Bayes, logistic regression and random forest classification algorithm.
Support-vector machine
In 1990s, Russian mathematician Vapnik and his colleagues proposed the model of Support-Vector Machines (SVM) to map vectors to a higher dimensional space, in which a maximum interval hyperplane is, established [65]. The model assumes that the larger the distance or gap between parallel hyperplanes, the smaller the total error of the classifier [66,67]. Through the construction of two categories of classifiers, each classifier needs to classify the content again secondarily, that is, build a large number of classification modules to input effective attribution set of X under the classifier system of different categories. Generally speaking, one-versus-rest method is mainly used to build K sub-classification systems using support-vector machine for k-class text problems, and it is necessary to mark the text samples belonging to then class as positive when building then sub-classification system. The text samples that do not belong to the class need to be marked as negative. With regard to the current study, the focus is a binary classification problem and chooses to apply one-versus-rest in Python scikit-learn as the algorithm.
Multinomial Naive Bayes (MNB)
Multinomial Naive Bayes (MNB) is suitable for random variables whose features are discrete. And the word vector used in text classification in this study is discrete, so MNB is chosen. Furthermore, MNB is one of the commonly used algorithms in text classification tasks [68]. The general formula of the algorithm is shown in formula (1).
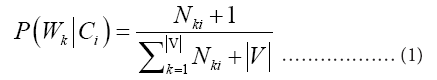
In the formula, NKi is the total number of occurrences of Ci documents in category of Wk, and |V| is the total number of words in the training data set.
Logistic regression
Logistic Regression (LR) is one algorithm for classification and prediction. By establishing a loss function, and then iteratively solving the optimal model parameters through optimization method, one can test and verify the quality of a solving model. Afterwards, the verified model can predict the probability of a certain disease or situation under different independent variables [69]. The common formulas of logistic regression are shown in formula (2) and formula (3).
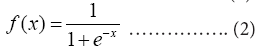
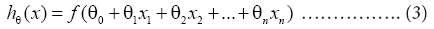
These algorithms are generally used to deal with regression problem in which the dependent variable is a binary variable. Therefore, in this study, logistic regression is applied to deal with the multi-classification problem based on one-versus-rest method.
Random forest
Building upon decision tree learning for individuals, random forest extends the algorithm by adding random sample selection and random feature selection. The steps are as the followings. Bootstrap sampling is used to extract K samples from the original training set, and each sample size is the same as that of the original training set. Then, K decision tree models are established for K samples to obtain K classification results. Finally, according to K classification results, each record is voted to determine its final classification.
TF-IDF sentence similarity method
This method believes that in two sentences, the more the same vocabulary, the higher and the similarity of the two sentences [70].
Specifically:
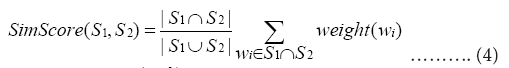
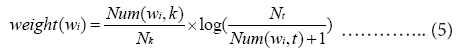
Among them, |•| is the cardinality of the set, S1 and S2 are the word sets of the two sentences to be compared, wi represents the symptom word i in the department question and answer sentence, weight (wi) is the TF-IDF weight, Num (wi,k) represents the number of sentences in which the symptom word wi appears in the question and answer sentence set of department k, Nk represents the number of all questions and answers in department k, Nt represents the total number of questions and answers in the knowledge base, and Num (wi,t) represents the total number of questions and answers in the knowledge base, The number of sentences in which the symptom word i appears in the question. The TF-IDF sentence similarity calculation method based on co-occurring words belongs to the surface structure analysis method. It simply uses the surface information of the sentence, that is, the word frequency, part of speech and other information of the words in the sentence to calculate the sentence similarity, without considering synonyms. This results in a decrease in the accuracy of sentence similarity [37].
Word vector sentence similarity method
Word vector sentence similarity is mainly used in-depth learning tool word2vec to process words into vectors, and obtains the semantic similarity of sentence pairs to be compared by calculating the similarity between vectors [71].
The specific formula is as follows:
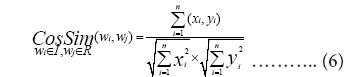
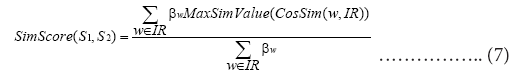
Among them, IR=S1 ∪ S2, wi and wj are the two words to be compared, which represent the words in sentence S1 and the words in sentence S2 respectively; n represents the dimension of the word vector, and xi and yi represent the word vector of wi and The vector value of the i-th dimension of the word vector of wj; MaxSimValue(CosSim(w,•)) represents the maximum value of the cosine similarity between the word vector corresponding to word w and the word vector corresponding to all vocabulary of another sentence; parameter βw is The TF-IDF weight value of word w in the sentence. The greater the value of SimScore(S1, S2), the greater the similarity between the two sentences and the closer the semantics.
Results and Discussion
Selection of optimal classifier
This study compared the accuracy of two text vectorization methods utilizing four machine learning algorithms, in which accuracy was measured by calculating ratio of the number of paired samples to the number of all samples. The two text vectorization methods were word2vec and TF-IDF (referring to term frequency-inverse document frequency). As for the word2vec method, it allows for expressing a word into vector form effectively according to a given corpus, retaining word order information to a large extent. It makes use of the characteristics of text adjacency and thus has better fitting ability. As for TF-IDF method, it requires the words to be not only highly frequent but also significantly distinguishing with each other. The results are shown in Table 2. Generally speaking, support-vector machine algorithm using word2vec to extract text features illustrated the highest accuracy rate of 76.4%. When the vectorization mode was TF-IDF, the accuracy rate of logistic regression algorithm was 74.1%, illustrating alright effect. The accuracy rates of multinomial Bayesian algorithm using both two text vectorization methods were the lowest, being 71.5% and 68.1% respectively. In conclusion, the text vectorization method of word2vec and the classification algorithm of support-vector machine were selected as the optimal classifiers, and its recommendation effect on the test set would be further analyzed and verified.
| Classification method | word2vec (%) | TF-IDF (%) |
|---|---|---|
| Support-vector machine | 76.4 | 73 |
| Random forest | 75.6 | 69 |
| Multinomial naive Bayes | 71.5 | 68.1 |
| Logistic regression | 73.2 | 74.1 |
Table 2: Comparison of accuracy rate.
Comparison of department recommendation accuracy rate
To further test the effect of support-vector machine in intelligent recommendation of secondary departments, recommendation accuracy rates for different secondary departments were calculated respectively as shown in Table 3 and Figure 2. The results showed that there was no significant correlation between data size of 20 secondary departments and the accuracy rate of recommendation (t=1.264, P=0.510). The data size difference of different departments did not directly affect recommendation accuracy. Individually speaking, among the 20 secondary departments, 17 of them illustrated accuracy rate of more than 65%. The accuracy rate of breast surgery department was the highest, close to 97%, followed by ophthalmology department with accuracy of nearly 94%. There were 6 secondary departments with accuracy rate of 80%-90%, and 11 secondary departments with accuracy rate of 70%-80%. On the whole, the algorithms performed good prediction even though accuracy rates for all departments and secondary departments’ recommendation were different, except for the surprising fact that the intelligent recommendation accuracy of general surgery department was only about 52.7%. General surgery is one of the most common departments at both online consultation platforms and offline hospitals. The diversity of patients’ consultation questions is also expected to be much higher. It is necessary to further analyze the reasons behind and find out potential methods to improve the accuracy of intelligent recommendation.
| Department | Secondary department | Data size | Accuracy rate of recommendation (%) |
|---|---|---|---|
| Internal medicine department | Neurology department | 713 | 73.2 |
| Endocrinology department | 318 | 72.6 | |
| Rheumatology and immunology department | 514 | 72.9 | |
| Surgical department | Urology department | 465 | 56.3 |
| Breast surgery department | 436 | 96.8 | |
| General surgery department | 1170 | 52.7 | |
| Department of gynecology and obstetrics | Gynecology department | 908 | 84.6 |
| Obstetrics department | 378 | 84.2 | |
| Department of orthopedics | Spine surgery department | 412 | 74.6 |
| Joint surgery department | 317 | 73.9 | |
| Traumatic orthopedics department | 324 | 72.8 | |
| Department of otolaryngology | E.N.T department | 380 | 84.6 |
| Ophthalmology department | 291 | 93.9 | |
| Head and Neck surgery department | 269 | 83.2 | |
| Department of dermatology | Department of dermatology | 781 | 65.2 |
| Andrology department | Andrology department | 413 | 74.3 |
| Pediatric department | Pediatric department | 376 | 66.3 |
| Psychiatry department | Psychiatry department | 420 | 78.2 |
| Department of cardiology | Department of cardiology | 268 | 77.5 |
| Department of stomatology | Department of stomatology | 584 | 86.4 |
Table 3: The accuracy rates of recommendation for different departments.

Figure 2: The accuracy rates of recommendation for different departments.
Improvement of recommendation effectiveness
Feature selection of classification can effectively improve accuracy rate of recommendation [72]. Weyi-Doctor platform requires patients to register an account before consulting doctors online, providing information such as age, gender, region, etc. After extracting 57632 pieces of data, only 38766 of them included both age and gender information. These 38766 pieces of data were therefore taken as samples for further analysis.
Average age and male-female ratio of patients from all 20 secondary departments were analyzed and the results are shown in Table 4. In terms of age, the overall average age of 20 secondary departments was 31.87- year old. The minimum was 12.9-year old for pediatrics department while the maximum was 48.6-year old for department of rheumatology and immunology. In terms of gender ratio, it demonstrated a great deviation for four secondary departments of andrology, gynecology, obstetrics and breast surgery due to their particularities. Even though people may consult doctors for their spouses, the cases were relatively rare after all. In addition, 64% of urological patients were male, while females were more likely to ask about children-related pediatrics.
| Department | Secondary department | Age (mean) | Gender (%) | |
|---|---|---|---|---|
| Male | Female | |||
| Internal medicine department | Neurology department | 36.4 | 48 | 51 |
| Endocrinology department | 34.2 | 45 | 55 | |
| Rheumatology and immunology department | 48.6 | 39 | 61 | |
| Surgical department | Urology department | 31.4 | 64 | 36 |
| Breast surgery department | 33.5 | 3.5 | 96.5 | |
| General surgery department | 45 | 59 | 41 | |
| Department of gynecology and obstetrics | Gynecology department | 29.3 | 2.1 | 97.9 |
| Obstetrics department | 28.6 | 4.9 | 95.1 | |
| Department of orthopedics | Spine surgery department | 33 | 53 | 47 |
| Joint surgery department | 46.2 | 55 | 45 | |
| Traumatic orthopedics department | 38.7 | 58 | 42 | |
| Department of otolaryngology | E.N.T department | 34.5 | 46.9 | 53.1 |
| Ophthalmology department | 27.6 | 47.6 | 52.4 | |
| Head and Neck surgery department | 31.3 | 47.8 | 52.2 | |
| Department of dermatology | Department of dermatology | 23.4 | 46.2 | 53.8 |
| Andrology department | Andrology department | 25.8 | 96.8 | 3.2 |
| Pediatric department | Pediatric department | 12.9 | 37.8 | 62.2 |
| Psychiatry department | Psychiatry department | 35.7 | 45.5 | 44.5 |
| Department of cardiology | Department of cardiology | 46.2 | 50.2 | 49.8 |
| Department of stomatology | Department of stomatology | 28.6 | 43.7 | 46.3 |
| Total | 31.87 | 41.8 | 58.2 | |
Table 4: Patients’ average age and gender difference for varying departments.
The above results find that age and gender attributes have their own characteristics for some specific departments. Therefore, these two feature-attributes and patients’ question texts shall be both trained as input variables. This study compares accuracy rate of department recommendation before and after the addition of feature characteristics. As shown in Table 5 and Figure 3, the overall accuracy rate was 78.5% before adding features, and rose to 79.4% after adding features. Concerning specific secondary departments, the increasing ranges were 4.2% and 3.9% respectively for andrology department that serves a significantly larger proportion of male patients and pediatrics department that is characteristics of lower-aged patients. Then, breast surgery department, urology department, gynecology department and obstetrics department followed successively with the increasing range of 0.62%, 0.6%, 0.6% and 0.6% respectively [73-75].
| Department | Secondary department | Accuracy beforehand (%) | Accuracy afterwards (%) | Change of accuracy rate (%) |
|---|---|---|---|---|
| Internal medicine department | Neurology department | 73.2 | 73.6 | 0.4 |
| Endocrinology department | 72.6 | 72.99 | 0.39 | |
| Rheumatology and immunology department | 72.9 | 73.32 | 0.42 | |
| Surgical department | Urology department | 56.3 | 56.9 | 0.6 |
| Breast surgery department | 96.8 | 97.42 | 0.62 | |
| General surgery department | 52.7 | 53.3 | 0.5 | |
| Department of gynecology and obstetrics | Gynecology department | 84.6 | 85.2 | 0.6 |
| Obstetrics department | 84.2 | 84.8 | 0.6 | |
| Department of orthopedics | Spine surgery department | 74.6 | 75.15 | 0.55 |
| Joint surgery department | 73.9 | 74.45 | 0.55 | |
| Traumatic orthopedics department | 72.8 | 73.35 | 0.55 | |
| Department of otolaryngology | E.N.T department | 84.6 | 84.6 | 0 |
| Ophthalmology department | 93.9 | 93.9 | 0 | |
| Head and Neck surgery department | 83.2 | 83.2 | 0 | |
| Department of dermatology | Department of dermatology | 65.2 | 65.3 | 0.1 |
| Andrology department | Andrology department | 74.3 | 78.5 | 4.2 |
| Pediatric department | Pediatric department | 66.3 | 70.2 | 3.9 |
| Psychiatry department | Psychiatry department | 78.2 | 78.3 | 0.1 |
| Department of cardiology | Department of cardiology | 77.5 | 77.95 | 0.45 |
| Department of stomatology | Department of stomatology | 86.4 | 86.8 | 0.4 |
| Total | 78.5 | 79.4 | 0.9 |
Table 5: The change of accuracy rate before and after addition of features of age and gender.

Figure 3: The change of accuracy rate before and after addition of features of age and gender.
Conclusion
Based on patients’ real online diagnosis-treatment data, the study applies four different machine learning algorithms to analyze the effect of intelligent department recommendation at online diagnosis-treatment platform. The findings are as the followings. First, support-vector machine and random forest are more suitable for the recommendation task overall. The finding verifies the advantages of support-vector machine in dealing with text classification in high- dimensional and sparse environment. Second, the classification algorithms suitable for different ways of text vectorization are varying in that support-vector machine and random forest are more suitable for more fitting word2vec while logistic regression is suitable for text vectorization prediction with TF-IDF method. Third, the accuracy rates for secondary department recommendation are discrepant. Among which, the accuracy rate of breast surgery department was the highest, close to 97%, followed by ophthalmology, close to 94%. Moreover, the accuracy rate of general surgery department recommendation was only 52.7%. The reason behind low accuracy rate may be due to the overlap between departments and some diseases represent the nature of multi-departments. For instance, both gynecologists and obstetricians can provide consulting service for questions regarding pregnancy and abortion.
When exploring how to improve recommendation accuracy, two feature attributes of age and gender were taken into account according to the characteristics of the data obtained. After removing around 19000 pieces of data with missing values on age and gender, the accuracy rate of recommendation was improved by 0.9%, which indicates that data quality is as important as data size when improving the effectiveness of machine learning algorithm. After adding characteristic vales of age and gender, recommendation accuracy for departments that confront with patients of male sex and lower age would be improved greatly, proving that extracting more data features is one direction to improve the recommendation accuracy.
Taking the perspective of department categorization, different from traditional mode of medical service, the department categorization at the online diagnosis-treatment platform tends to be more flat-structured. To be specific, based upon department setting of offline hospitals, WeDoctor platform optimizes department categorization by adding secondary departments after considering the demand characteristics of online diagnosis-treatment. For instance, because of the large demand for online consultation, department of orthopedics is set independently as a first-class department category though it traditionally belongs to surgery department. Moreover, the relationship between a certain disease and the department is sometimes not one-to-one, but one-to- many. For instance, a 4-year-old child coughing may be suitable for pediatrics or internal medicine department. Therefore, since patients may not know enough about department and its scope of diagnosis- treatment, they would have doubts in the process of consultation. The implementation of intelligent recommendation can exactly help reduce pressure and burden of patients in choosing department so as to improve efficiency of diagnosis-treatment by enabling the platform to provide personalized recommendation for patients’ specific conditions. The literature shows that the mode of online diagnosis-treatment service is becoming more patient-centered and problem-oriented. By intelligently matching relevant departments directly with patients’ online problems, the intelligent department recommendation task represents one way to optimize problem-oriented online diagnosis- treatment process, improving patients’ satisfaction as a result.
The current study is not without limitations. First, this study assumes that the department selected by patients in the data is correct, which may not be the case in reality. Second, for intelligent department recommendation tasks, in addition to controlling data quality, deep learning algorithms such as LSTM shall be applied to improve model accuracy in the future. Third, the intelligent department recommendation task can also be abstracted as a multi-label classification task for texts. Accordingly, multiple department categories can be recommended for patients’ questions covering multiple departments. Fourth, patient’s regional information shall be taken into account in the model to more accurately recommend doctors, improving convenience of offline medical treatment for patients.
Fund Program
National Natural Science Foundation of China (71571162).
Authors’ Contributions
SZ and CH refined the topics and methods at the initial stage of paper writing. Then, SZ conducted the statistical analysis and wrote the paper under the guidance of CH. Both authors reviewed, revised, and approved the final draft.
Conflicts of Interest
None declared.
References
- Jinping X (2022) Endeavoring for a new era.
- Zhou H (2019). Design and implementation of knowledge base for runtime management of software Defined hardware. IEEE 11:163-182.
- Wang P, Ding Z, Jiang C, Zhou M (2013) Design and implementation of a web-service-based public-oriented personalized health care platform. IEEE Trans Syst Man Cybern Syst 4: 941-957
- Lin Y, Huang L, Wang Z (2015) Proceedings of the 2015 International conference on Applied Science and Engineering Innovation. Adv Eng 17:33-40.
- Lin Y, Huang L, Wang M (2015) An intelligent medical guidance system based on multi-words TF-IDF algorithm. J Appl Sci Eng 11:15-24.
- Chuan-peng C, Zhi-gang W (2012) A method of sentence similarity computing based on Hownet. Comput Sci Eng 34:172-175.
- Yifeng X, Lijun L, Qingsong H (2017) Research on TF-IDF weight improvement algorithm in intelligent guidance system. Comput Appl Eng 53:238-243.
- Wei C, Qingkai B (2018) A review of the research on mobile internet recommendation system. Comp Knowl Technol 11: 29-31.
- Ii-media. Global new economy industry research database. 2011.
- Pineda A, Ye Y, Visweswaran S, Cooper G, Wagner M, et a1. (2015) Comparison of machine learning classifiers for influenza detection from emergency department free-text reports. J Biomed Inform 58:60-69.
[Crossref] [Google Scholar] [Pubmed]
- Qian K, Dujuan W, Yanzhang W, Yaochu J, Bin J (2018) Multi-objective neural network-based diagnostic model of prostatic cancer. Syst Eng Theory Pract 38:532-544.
- Nikfarjam A, Sarker A, O’connor K, Rachel G, Gonzalaz G (2015) Pharmacovigilance from social media:mining adverse drug reaction mentions using sequence labeling with word embedding cluster features. J Am Med Inform Assoc 22:67l-681.
[Crossref] [Google Scholar] [Pubmed]
- Kose I, Gokturk M, Kilic K (2015) An interactive machine-learning-based electronic fraud and abuse detection system in healthcare insurance. Appl Soft Comput 36:283-299.
- Wang W, Xie Y, Liu K (2017) Research on virtual health community users willingness based on grounded theory. J Doc 38:75-82.
- Song X (2015) Urban local geothermal climate prediction and heat island effect mitigation strategies. J. Harbin Eng Univ 47:15-20.
- Fan X, Ai S (2016) An empirical study on the relationship between online medical community participants' behaviors and knowledge exchange effect. Inf Magazine 35:173-178. [Crossref] [Google Scholar] [Pubmed]
- Deng S, Liu B (1999) Modelling and forecasting the money demand in China: Cointegration and non‐linearanalysis. Ann Oper Res 87:177-189.
- Zhou J (2016) Examining the users' participation behavior types in online health communities: A qualitative approach. J Manag Case Stud 9:173-184.
- Liu X (2014) The impact of online doctor reputation and doctor effort on consultation amount. Harbin Institute of Technology.
- Wang J, Chiu Y, Yu H, Hsu Y (2017) understanding a nonlinear causal relationship between rewards and physicians’ contributions in online health care communities: longitudinal study. J Med Internet Res 19:82-90.
- Chengyu MA (2016) An empirical study on the interactive behavior of physicians and patients in online health community: A case study of Haodf.com. Chinese J Health Policy 9:65-69.
- Li C, Khan M (2022) Public trust in physicians: Empirical analysis of patient-related factors affecting trust in physicians in China. BMC Prim Care 30:43-52.
- Morgan R, Hunt S (1994) The commitment-trust theory of relationship marketing. J Mark 58:20-38.
- Wu J, Chen Y, Chung Y (2010) Trust factors influencing virtual community members: A study of transaction communities. J Bus Res 63:1025-1032.
- Piao J, Sun FC (2013) Doctor-patient trust under the perspective of doctors and patients. Chin Med Ethics 2013;26(6):772.
- Ridings CM, Gefen D, Arinze B (2002) Some antecedents and effects of trust in virtual communities. J Strategic Inf Sys 11(3-4):271-295.
- Li Y, Wang X, Guo R (2015) study of doctor-patient trust and influence factors based on the view of patients. Chin Hosp Manag 35(11):56-58.
- Dong E (2012) Empirical study of the impact of patients' trust on health outcomes. Chin J Hosp Adm 28(5):355-359.
- Sussman SW, Siegal WS (2003) Informational influence in organizations: An integrated approach to knowledge adoption. Inf Sys Res 14(1):47-65.
- Fang A, Li Y (2011) Computing algorithm of user similarity in virtual medical communities. J Med Inform 32:48-51.
- Park Y, Park S, Lee M (2022) Analyzing community care research trends using text mining. J Multidiscip Health 15:1493-1510.
- Zhao J, Wang T, Fan X (2015) Patient value co-creation in online health communities: Social identity effects on customer knowledge contributions and membership continuance intentions in online health communities. J Serv Manag 26:72-96.
- Ma Y, Fu H, Jiang Y (2008) Virtual community: valuable study area in health education in information age. Chin J Health Edu 24:296-297.
- Wu J, Hou S, Jin M (2017) Social support and user roles in a chinese online health community: a LDA based text mining study. Smart Health 36:1183-1191.
- Tiddi I, Schlobach S (2022) Knowledge graphs as tools for explainable machine learning: A survey. Artif Intell 5:97-105.
- Liang C, Liu Y, Du H (2017) Chinese text classification based On LDA and KSVM. Adv Comput Adv Com 36:1183-1191.
- Liu T, Yang J (2017) Evaluating online healthcare consultation feedbacks based on signal transmission algorithm. Data Anal Knowl Discov 1:29-36.
- Huang X, Zhang J, Xu Z, Ou L, Tong J (2021) A knowledge graph based question answering method for medical domain. Peer J Comput Sci 1:e667.
- Li H, Liu J, Shen W, Liu R, Jin S (2020) Recommending knowledge for online health community users based on fuzzy cognitive map. Data Anal Knowl Discov 4:55-67.
- Himmel W, Reincke U, Michelmann H (2009) Text mining and natural language processing approaches for automatic categorization of lay requests to web? Based expert forums. J Med Internet Res 11:e25.
[Crossref] [Google Scholar] [Pubmed]
- Abdaoui A, AzE J, Bringay S, Pascal P (2015) Assisting E-patients in all ask the doctor service. Stud Health Technol Inform 210:572-576.
[Google Scholar] [Pubmed]
- Yan Y, Yu G, Yan X (2020) Online doctor recommendation with convolutional neural network and sparse inputs. Comput Intell Neurosci 2020:1-10.
- Zheng Y, Jiang Z, Xie F, Shi J, Zhang H, et al.(2021) Diagnostic regions attention network (DRA-Net) for histopathology WSI recommendation and retrieval. IEEE 40:1090-1103.
- Loftus T (2022) Ideal algorithms in healthcare: explainable, dynamic, precise, autonomous, fair, and reproducible. Digit Health 1:e0000006.
- Pengfei S, Zhanzhong J (2017) Optimization of SRAP-PCR system on Glycyrrhiza uralensis by orthogonal test design and selection of primers. He bei J Ind Sci Techol 34:125-129.
- Shaw P,Uszkoreit J, Vaswani A (2018) Self-attention with relative position representations. Comput Lang 18:21-55.
- Zhen R, Jiaxing Y, Zhao G, Xueli W (2019) Simulation research on UAV recognition method based on convolutional neural-network. J Hebei Univ Sci Techol 40:397-403.
[Crossref]
- Yang Y, Liu B, Qi M (2014) Review of information visualization. J Hebei Univ Sci Techol 35:91-102.
[Crossref]
- Zhang S, Yao L, Sun A, Tay Y (2018) Deep learning based recommender system: a survey and new perspectives. ACM Comput Surv 1:45-69.
- Chen N. Research on recommendation system based on deep learning. Guilin: Guilin University of Electronic Technology, china. 2019.
[Crossref]
- Aytug O (2017) Hybrid supervised clustering based ensemble scheme for text classification. Kybernetes 46:330-348.
- Aytug˘ O, Serdar K (2015) A feature selection model based on genetic rank aggregation for text sentiment classification. J Inf Sci 43:25-38.
- Aytŭg O (2020) Sentiment analysis on product reviews based on weighted word embeddings and deep neural networks. Concurr Comput Pract Exp. 2:e5909.
- Aytuğ O (2019) Mining opinions from instructor evaluation reviews: A deep learning approach. Comput Appl Eng Educ 28:117-138.
- Aytuğ O (2019) Topic-enriched word embeddings for sarcasm identification. Comp Sci On-line Conf. 984:293-304.
- Aytug O, Mansur A (2021) A term weighted neural language model and stacked bidirectional LSTM based framework for sarcasm identification. IEEE 9:7701-7722.
- Aytug O (2016) An ensemble scheme based on language function analysis and feature engineering for text genre classification. J Inf Sci 44:28-47.
- AytuL O (2018) Biomedical text categorization based on ensemble pruning and optimized topic modelling. Comput Math Methods Med 2018:1-22.
- Aytug O (2015) Classifier and feature set ensembles for web page classification. J Inf Sci 42:150-165.
- Aytuğ O, Serdar K, Hasan B (2016) Ensemble of keyword extraction methods and classifiers in text classification. Expert Syst Appl 57:232-247.
- Aytu˘g O (2019) Consensus clustering-based undersampling approach to imbalanced learning. Sci Program 2019.
- Aytug O (2016) A fuzzy-rough nearest neighbor classifier combined with consistency-based subset evaluation and instance selection for automated diagnosis of breast cancer. Expert Syst Appl 42:6844-6852.
- Aytuğ O,Vedat B, Burcu Y (2016) The use of data mining for strategic management: a case study on mining association rules in student information system. Croat J Educ 18:41-70.
- Aytuğ O (2019) Two-stage topic extraction model for bibliometric data analysis based on word embeddings and clustering. IEEE 7:145614-145633.
- Vapnik V. The nature of statistical learning theory.(2nd edn). New York: springer, United States,1999.
- Burges J (1998) A tutorial on support vector machines for pattern recognition. Data Min Knowl Discov 2:121-167.
- Alex J, Bernhard S (2004) A tutorial on support vector regression. Stat Comput 14:199-222.
- Kibriya A, Frank E, Pfahringer B, Geoffrey H (2004) Multinomial naive bayes for text categorization revisited. Australasian Joint Conf Artif Intell 2004.
- Li H. Statistical learning methods. Beijing: Tsinghua University Press, China, 2012.
- Holman H, Lorig K (2004) Patient self-management: a key to effectiveness and efficiency in care of chronic disease. Public Health Rep 119:239-243.
- Xiong H, Li J (2012) Why people use social networking sites: An empirical study integrating network externalities and motivation theory. Comput Hum Behav 35:17-22.
- Xian W, Xing Y, Hao Y, Xing T, Shu S (2020) TLS point cloud classification of forest based on nearby geometric features. J Cent South Univ Technol 3:1-7.
- Wang H, Ye P, Deng S (2014) The application of machine learning in the research on automatic categorization of chinese periodical articles. New Technol Libr Inf Sci 30:80-87.
- Ishikawa H, Hashimoto H, Kiuchi T (2013) The evolving concept of “Patient-Centeredness” in patient-physician communication research. Soc Sci Med 96:147-153.
[Crossref] [Google Scholar] [Pubmed]
- Zhao M, Du H, Dong C, Chen C (2017) Diet health text classification based on Word2Vec and LSTM. J Agric Mac 48:202-208.
Citation: Zhang S, Ju C (2022) Online Diagnosis-Treatment Department Recommendation based on Machine Learning in China. Diagnos Pathol Open S12 :001. DOI: 10.4172/ 2476-2024.7.S12.001
Copyright: © 2022 Zhang S, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Share This Article
Open Access Journals
Article Tools
Article Usage
- Total views: 2151
- [From(publication date): 0-2022 - Mar 31, 2025]
- Breakdown by view type
- HTML page views: 1788
- PDF downloads: 363